Vision Transformer
Introduction
These are my study notes on Vision Transformers:
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021.
Very nice visualization of Fig.1 of [Dosovitskiy et al. 2021] by Phil Wang (lucidrains):
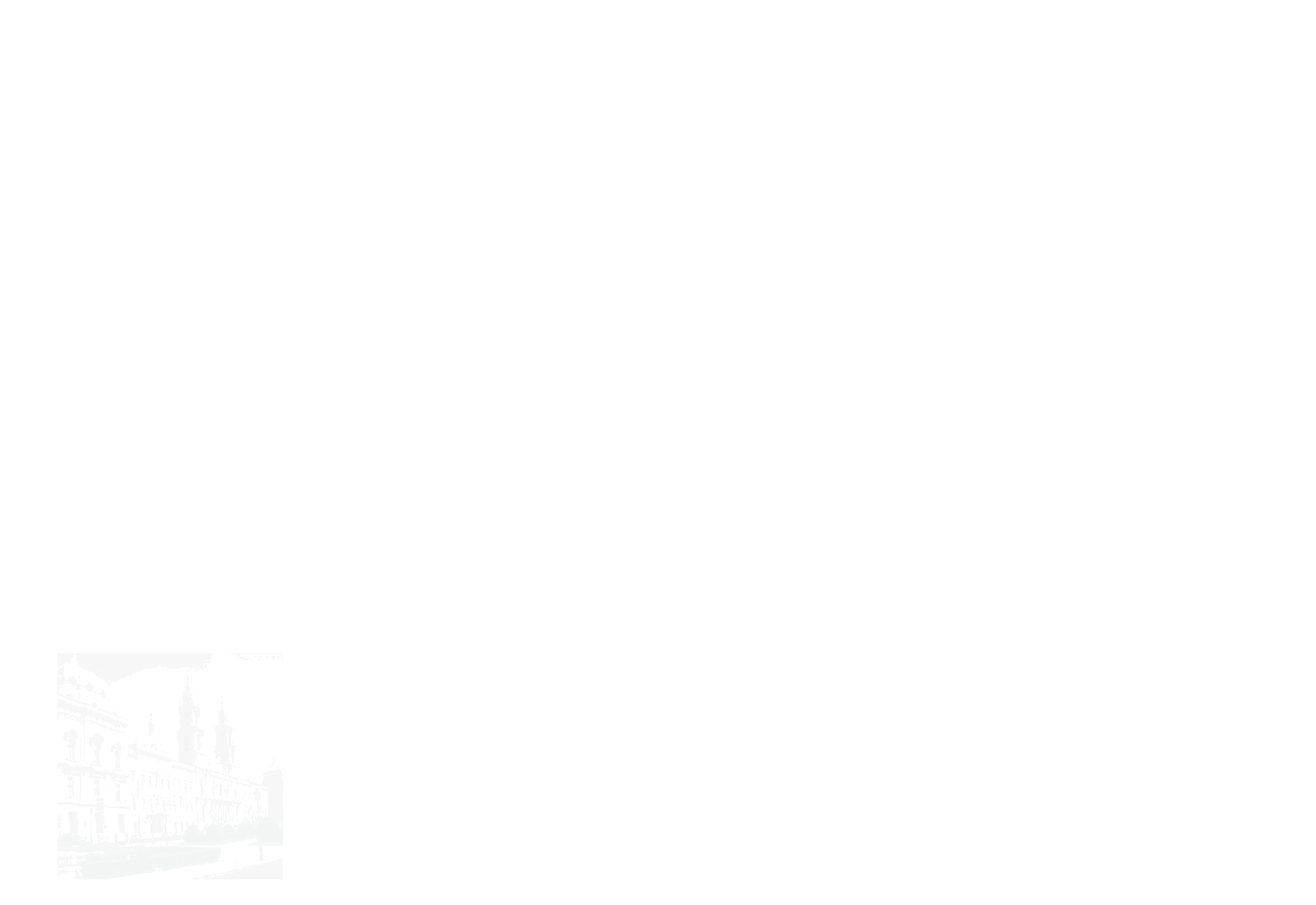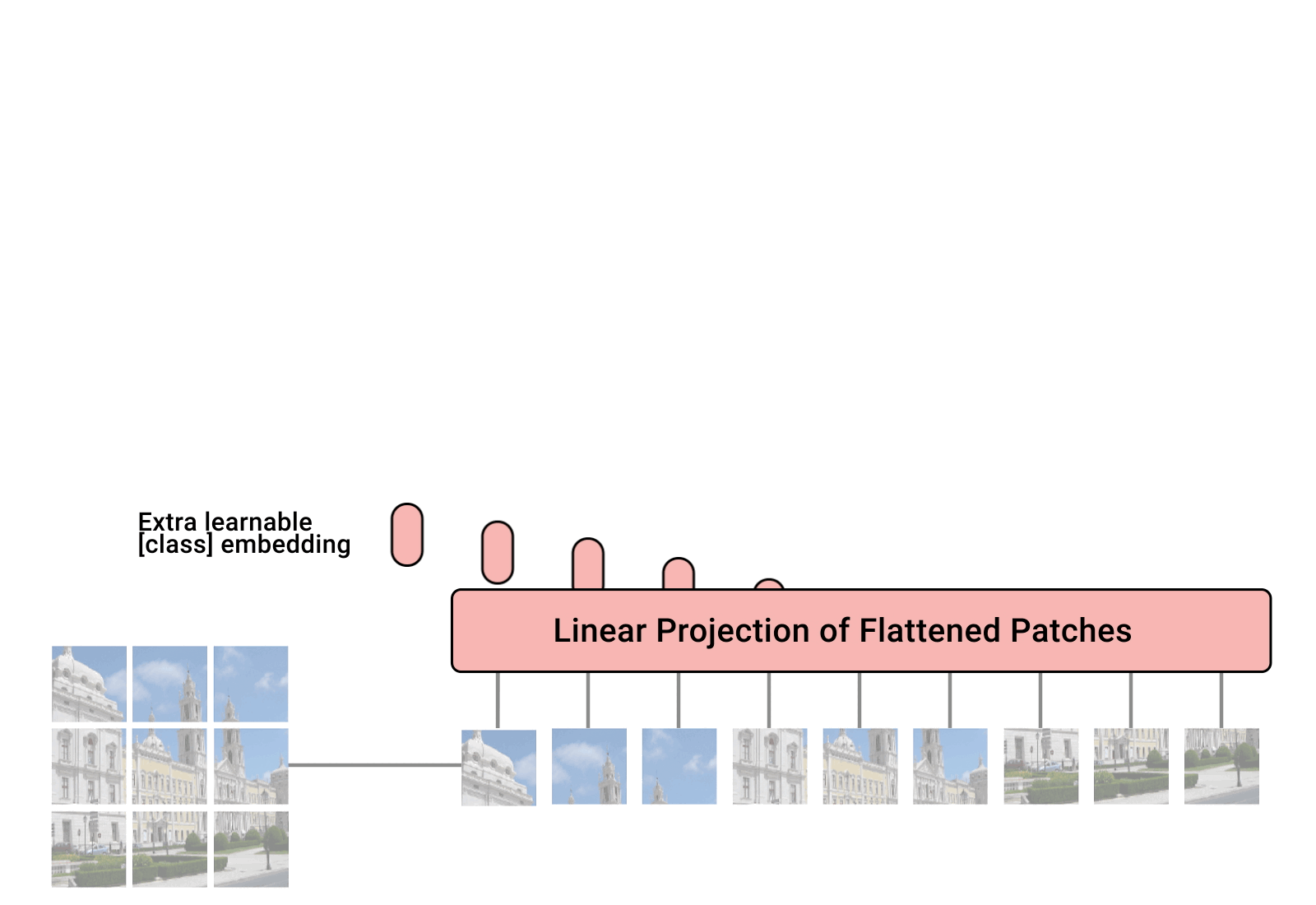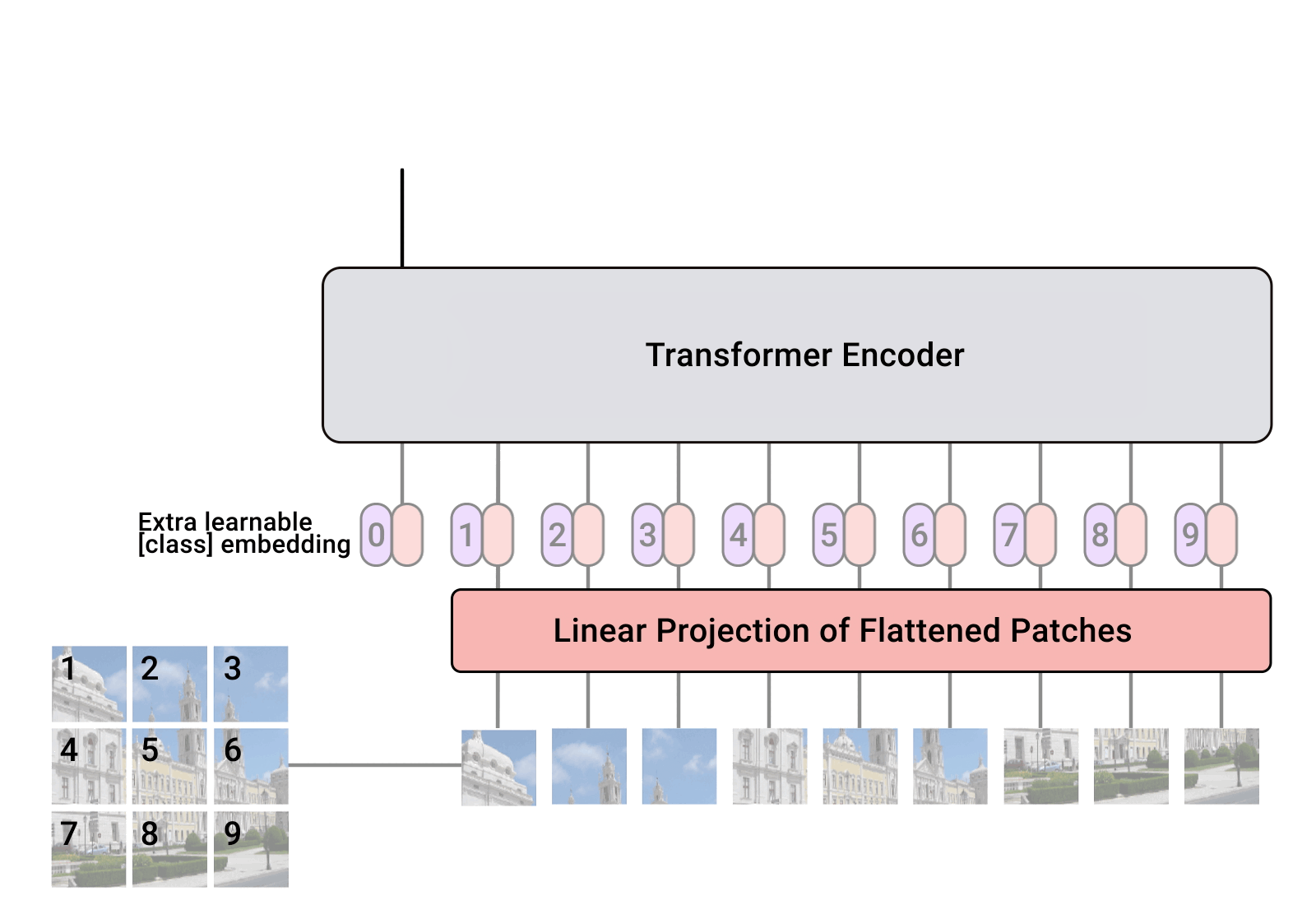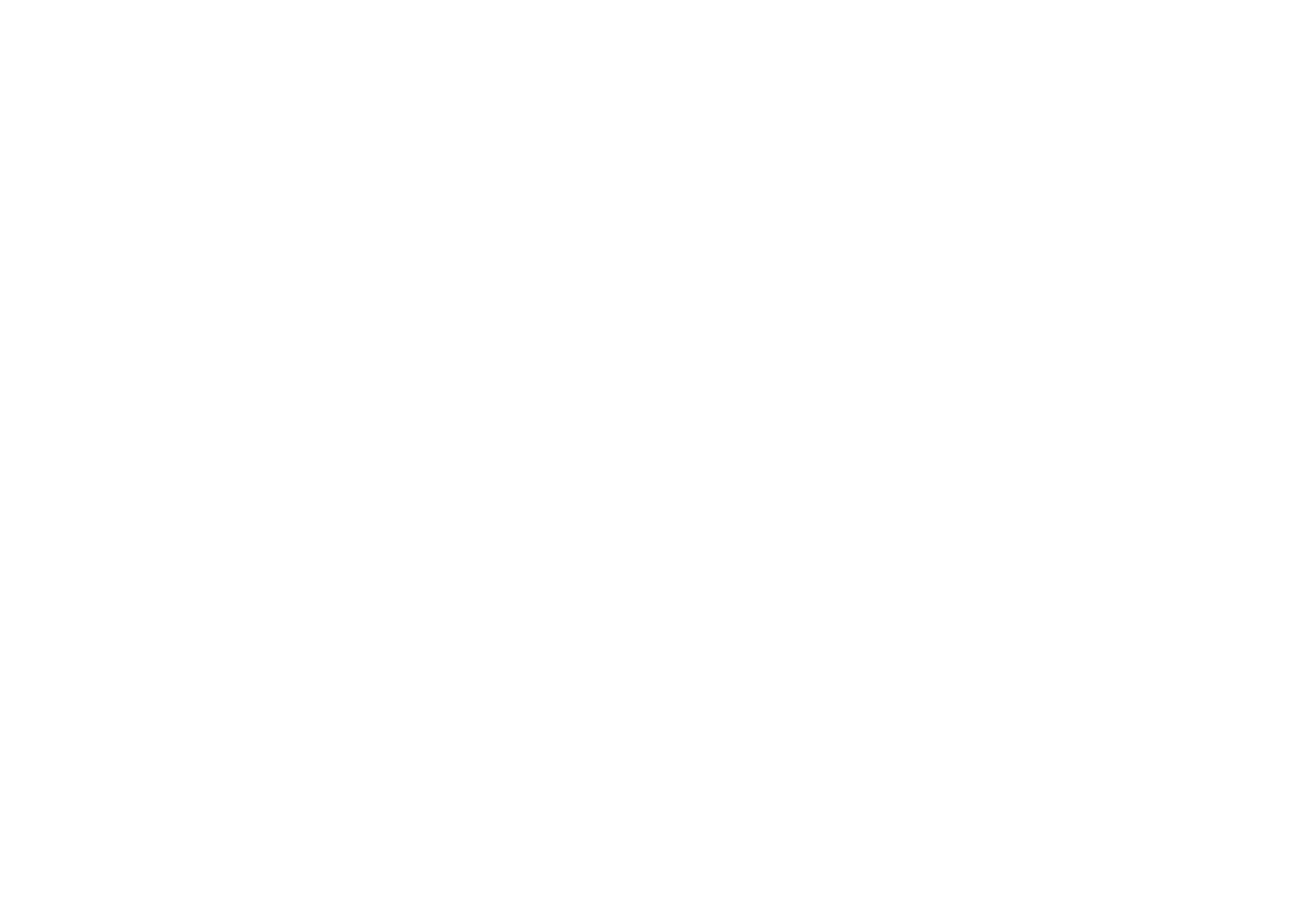
Patchification
- An image \({\bf x}\) of shape
(H, W, 3)is split into fixed sized patches, where each patch has shape(P, P, 3).- We have 9 patches in the figure.
- \(P\) can be 16 for “16x16 words”.
- Each patch is flattened to a row vector \({\bf x}_p^i\) of length \(3P^2\), for \(i=1,2, \cdots, 9\).
- Linearly embed each of \({\bf x}_p^i\), for \(i=1,2, \cdots, 9\), i.e. \({\color{red} {\bf x}_p^i {\bf E}}\).
- \({\color{red} {\bf E}}\) is a \(3P^2 \times D\) matrix.
- Prepend a learnable embedding \({\bf x}_{class}\) (“classification token”) to the sequence of embedded patches to obtain a \(10 \times D\) matrix
- Add position embeddings \({\bf E}_{pos}\) ( Eq (1) in [Dosovitskiy et al. 2021] ):
The learnable embedding and the position embedding are implemented in PyTorch using nn.Parameter.
[Phill Wang’s implementation]:
# x_class
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# E_pos
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
The 10 row vectors or ``embedded patches’’ in \({\bf z}_0\) are fed to a standard transformer encoder, which we will describe next.
Transformer Encoder
A transformer encoder is formed by stacking \(L\) transformer encoder layers.
Suppose the \(l\)-th layer is denoted by a function \(f_{\theta^{(l)}}\), where \(\theta^{(l)}\) represents the neural network paramters of the \(l\)-th layer.
The 10 embedded patches in \({\bf z}_0\) are fed to the first transformer encoder layer \(f_{\theta^{(1)}}\).
\[{\bf z}_1 = f_{\theta^{(1)}} ({\bf z}_0)\] \[{\bf z}_2 = f_{\theta^{(2)}} ({\bf z}_1)\] \[\ \ \ \ \ \ \ \vdots\] \[{\bf z}_L = f_{\theta^{(L)}} ({\bf z}_{L-1})\]Note that \({\bf z}_l \in \mathbb{R}^{10 \times D}\), for \(l=0, 1,2, \cdots, L\),
\[{\bf z}_l = \left[ \begin{matrix} && {\color{red}{\bf z}_l^0} &&\\ && {\color{green}{\bf z}_l^1} &&\\ && \vdots &&\\ && {\bf z}_{l}^{9} && \end{matrix} \right],\]where \({\bf z}_l^i\) is a \(1 \times D\) vector. We refer to \({\bf z}_l^i\) as an “embedding” or a “latent representation” of the image patch \(i\).
The function \(f_{\theta^{(l)}}\) consists of a self-attention layer and an MLP block (CS182, lecture 12, Video Recording).
- The self-attention layer exchanges information between image patch positions.
- The MLP post-processes the information from the previous attention layer, and prepares it for the next attention layer.
- The same MLP is applied independently at every image patch position.
The function \(f_{\theta^{(l)}}\) performs the following:
\[{\bf z}_l' = {\color{green}\mbox{MSA}}(\mbox{LN}({\bf z}_{l-1})) + {\bf z}_{l-1}\] \[{\bf z}_l = {\color{blue}\mbox{MLP}}(\mbox{LN}({\bf z}_l')) + {\bf z}_l' = f_{\theta^{(l)}} ({\bf z}_{l-1})\]Notice how the transformer transforms the input \({\bf z}_0\) to the output \({\bf z}_L\):
\[\left[ \begin{matrix} && {\color{red}{\bf z}_0^0} && \\ && {\color{green}{\bf z}_0^1} &&\\ && \vdots &&\\ && {\bf z}_{0}^{9} && \end{matrix} \right] \rightarrow \left[ \begin{matrix} && {\color{red}{\bf z}_1^0} &&\\ && {\color{green}{\bf z}_1^1} &&\\ && \vdots &&\\ && {\bf z}_{1}^{9} && \end{matrix} \right] \rightarrow \left[ \begin{matrix} && {\color{red}{\bf z}_2^0} &&\\ && {\color{green}{\bf z}_2^1} &&\\ && \vdots &&\\ && {\bf z}_{2}^{9} && \end{matrix} \right] \rightarrow \cdots \rightarrow \left[ \begin{matrix} && {\color{red}{\bf z}_{L-1}^0} &&\\ && {\color{green}{\bf z}_{L-1}^1} &&\\ && \vdots &&\\ && {\bf z}_{L-1}^{9} && \end{matrix} \right] \rightarrow \left[ \begin{matrix} && {\color{red}{\bf z}_L^0} &&\\ && {\color{green}{\bf z}_L^1} &&\\ && \vdots &&\\ && {\bf z}_{L}^{9} && \end{matrix} \right]\]Using the self-attention layer in \(f_{\theta^{(l)}}\), the patch embeddings in the matrix \({\bf z}_{l-1}\) communicate with each other and become the patch embeddings in \({\bf z}_l\). For example, \({\bf z}_{l-1}^0\) talks with \({\bf z}_{l-1}^1, {\bf z}_{l-1}^2, \cdots, {\bf z}_{l-1}^9\) to become \({\bf z}_l^0\).
The input \({\bf z}_0\) and the output \({\bf z}_L\) have the same dimension, and \({\bf z}_0^i\) in \({\bf z}_0\) eventually becomes \({\bf z}_L^i\) in \({\bf z}_L\).
Image Classification
Recall that \({\bf x}_{class}\) is the top row of \({\bf z}_0\) denoted by \({\bf z}_0^0\). The patch embedding in \({\bf z}_L\) corresponding to \({\bf x}_{class}\) is its top row \({\bf z}_L^0\).
In Eq (4) of [Dosovitskiy et al. 2021], \({\bf z}_L^0\) is used for image classification. Alternatively, “mean-pooling” of the patch embeddings \(\frac{1}{10}\sum_{i=0}^{9} {\bf z}_L^i\) can be used.

In order to classify the image \({\bf x}\), we compute the logits as
\[{\bf o} = {\bf z}_L^0 {\bf W} + {\bf b},\]where \({\bf z}_L^0\) is a \(1 \times D\) vector, \({\bf W}\) is a \(D \times N_\text{class}\) matrix, and \({\bf b}\) is a \(1 \times N_\text{class}\) vector.
Then, we determine the softmax
\[\mbox{Softmax}({\bf o}) = \left[ \begin{matrix} p_1 \\ p_2 \\ p_3 \\ \vdots \\ p_{N_\text{class}} \end{matrix} \right]^T = \left[ \begin{matrix} P(\mbox{bird}|{\bf x}) \\ P(\mbox{ball}|{\bf x}) \\ P(\mbox{car}|{\bf x}) \\ \vdots \\ P(\mbox{zebra}|{\bf x}) \end{matrix} \right]^T,\]where
\[p_i = \frac{\exp(o_i)}{\sum_{j=1}^{N_\text{class}} \exp(o_j)}\]In Phill Wang’s implementation,
# x == z_0
x = self.transformer(x) # (batch_size, 10, D)
# x == z_L
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
return self.mlp_head(x)